活用しませんか — テキストマイニング、形態素解析
テキストデータから政策立案・ビジネスに活きる知見を導出する
テキストマイニング
「テキストマイニング」とは、大量の文章データを対象として、統計解析や自然言語処理などの手法を用いて、頻出語・特徴・関連性や傾向などの情報を抽出・分析する技術です。文章の構造や意味を整理し、知見の発見や意思決定に役立てることができます。
実例:ワードクラウド
一般によく用いられるテキストマイニングの手法に「ワードクラウド」があります。ワードクラウドは、文章中に出現する単語を頻度に応じて大きさや色で視覚的に表現した図のことです。頻繁に用いられる語ほど大きく表示されるので、文章の特徴やテーマをひと目で把握することができます。例えばマーケティングにおいて、消費者インタビューのテキストデータから嗜好性や価値観、ニーズなどを把握するために使用されます。
下図は、宮城県の南三陸町社会福祉協議会が2024年に開催した「小さな社協のこだわりフォーラム」(YouYubeで全議題の映像・音声が公開されています)における同町の福祉の未来像に関する参加者の発言内容を、当社がテキストデータ化した上でワードクラウドに表したものです。「コミュニティ」、「ボランティア」、「連携」といったキーワードの存在を確認することができることから、同社会福祉協議会メンバー向けワークショップに提出し、参加者同士の意見交換に活用しました。

形態素解析
「形態素解析」とは、日本語、英語、中国語などの自然言語を対象に、文章を最小の意味単位である「形態素」に分割し、その品詞や活用形などの文法情報を付与する処理のことです。文を品詞別に仕分けした上で、特定の単語同士の関係性を構造化することで、テキストの内容把握や統計分析、検索精度向上などの目的に活用することが可能となります。テキストマイニングの基盤技術であり、いま人口に膾炙しつつある生成AIの技術的基礎である大規模言語モデル(LLM)も、ルーツはこの形態素解析にあると言えます。
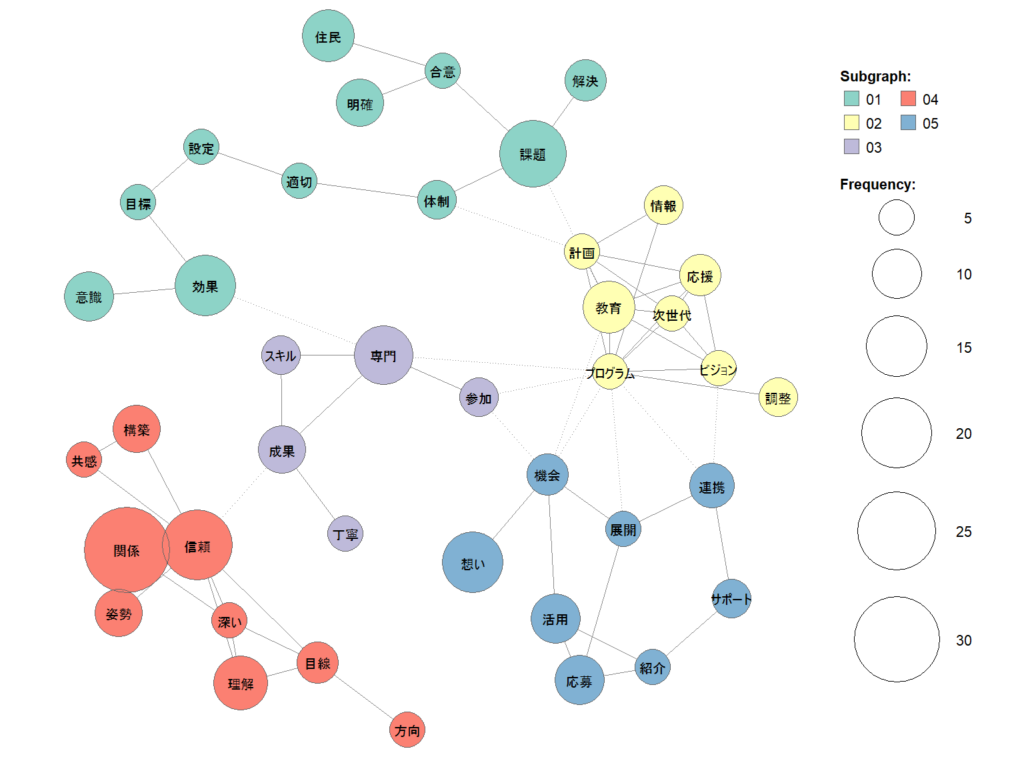
実例:共起ネットワーク分析
「共起ネットワーク分析」は、ある文章について上述の形態素解析を施した上で、文中の特定の単語同士が比較的高い頻度で同時に現れる関係(共起関係)をJaccard係数という統計量に基づいて特定・抽出し、それらをノード(単語)とエッジ(共起)からなるネットワーク図として可視化する分析手法です。単語間のつながりや文脈上の関連性、語彙のグループ単位での意味合いを把握する上で有効であり、テキストの特徴の理解や意味ある傾向の導出に活用されています。
下図は、復興庁が公開している『地域づくりハンズオン支援事業ハンドブック』(2025年3月発行)に載っている、ハンズオン支援実施上の要点に関する関係者(支援専門家)のコメントをテキストデータ化した上で、共起ネットワーク図にしたものです。関係性が強い単語をグループ化することで意味や文脈を読み取ることができます。この場合、課題解決に向けた合意(緑色)、ビジョン実現のための計画・プログラム作り(黄色)、専門性を有する人による支援(紫色)、関係者同士の共感・相互理解(赤色)、団体間連携や支援事業の活用(青色)などが支援の成否を左右するポイントであることが窺われます。
ご相談ください
上記のようなテキストマイニング手法を用いた分析に関心がある方や、実際にワードクラウドや共起ネットワーク分析を使った施策検討ニーズをお持ちの方は、ぜひ当社にご相談ください。
[お問い合わせ先]
株式会社リベルタス・コンサルティング 経済・地域戦略部
担当:五十嵐義明 (いがらし・よしあき)
電話:03-3511-2161 (当社本社代表)